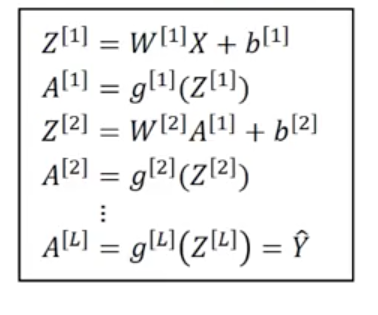Notes on Logistic Regression
Course 1 of Andrew Ng's Deep Learning Series
Course 2
Course 3
Welcome
AI is new electricity, transforming numerous industries.
Neural Network
Looks like this
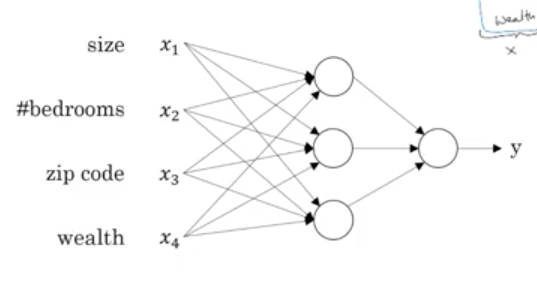
Multidimensional input goes to the neurons in first layer. Output of first layer neurons goes to second layer, and so on.
Housing problem is structured, ads clicked or not is structured. Audio, image, and are unstructured.
Deep learning is taking off now because there is lot of data to train on, and computing power to perform this training.
Logistic Regression
We are given $(x, y)$ pairs where $x \in R^{n_x}$ and $y \in \{0, 1\}$.
$x$ is written as a column vector.
We want $\hat{y} = P(y = 1 \mid x)$.
We denote those pairs as $(x^{(1)}, y^{(1)}), (x^{(2)}, y^{(2)}) \dots (x^{(m)}, y^{(m)}) $
We say $\hat{y} = \sigma(w^{T}x + b)$, or $\hat{y} = \sigma(z)$ where $z = w^{T}x + b$
by which we mean
$\hat{y^{(i)}} = \sigma(w^{T}x^{(i)} + b)$ for $i = 1\dots m$
where $w \in R^{n_x}$ is again a column vector, and $b \in R$ and
$\sigma(z) = \frac{1}{1 + e^{-z}}$
$w^T = [w_1, w_2, \dots w_{n_x}]$
$\sigma(z)$ called "activation function". There can be many activation functions. They are the
ones which give rise to non linearity in logistic regression and neural networks.
Now we need to find $w$ and $b$ such that cost function
$J(w,b) = \frac{1}{m} \sum_{i=1}^{m}L(\hat{y^{(i)}}, y^{i})$
is minimized, where
$L(\hat{y}, y) = -(ylog\hat{y} + (1 - y)log(1 - \hat{y}))$
$J$ is called cost function, $L$ is called loss function.
Gradient Descent to Solve the Problem
Main idea is, start with some value of $w$ and $b$, and then repeatedly:
$w_i = w_i - \alpha\frac{dJ(w,b)}{dw_i}$ for $i = 1\dots n_x$
$b = b - \alpha\frac{dJ(w,b)}{db}$
till $w$ and $b$ converge.
Now, for one training example, let us use $\hat{y} = a$.
$\frac{dL(a,y)}{dw_1} = \frac{dL(a,y)}{da}\frac{da}{dz}\frac{dz}{dw_1}$
where $z = \sigma({w^{T}x + b})$
It simplifies to
$\frac{dL(a,y)}{dw_1} = (-\frac{y}{a} + \frac{1-y}{1-a}) * a(1-a) * x_1$
$= (a - y)x_1$
Similarly, we can find that
$\frac{dL}{db} = \frac{dL}{dz}$
Some notation
We denote $da = \frac{dL(a,y)}{da}$, $dz = \frac{dL(a,y)}{dz}$ and $dw = \frac{dL(a,y)}{dw}$
Thus we write:
$dz = (a - y)$, $dw_i = x_idz$
Now, since you know $dw_i$, if there were just one training example, you could do
$w_i = w_i - \alpha dw_i$
repeatedly till $w_i$ converged.
But we have $m$ training examples.
Gradient descent on $m$ training examples
Thus, summing over $m$ training examples,
$\frac{dJ}{dw_1} = \frac{1}{m}\Sigma_{i=1}^{m}\frac{d}{dw_1}L(a^i, y^i)$
$= \frac{1}{m}\Sigma_{i=1}^{m}dw_1^{(i)}$
We call $dw_1 = \frac{dJ}{dw_1}$
and set $w_1 = w_1 - \alpha dw_1$
Similarly for $dw_2\dots dw_{n_x}$
And $b = b - \alpha db$
Vectorizing Logistic Regression
Since $x$'s are written as column vector, we can introduce
$X =
\begin{bmatrix}
\mid & \mid & & \mid\\
x^{(1)}& x^{(2)} & \dots & x^{(m)}\\
\mid & \mid & & \mid
\end{bmatrix}$,
$X \in R^{n_x \times m}$
Also, $Z = [z_1,\dots z_m]$
And, $W^T = [w_1, \dots w_{n_x}]$. Note that we just declare $W = w$
So, $Z = W^TX + b$
$A = \sigma(Z)$
$dZ = A - Y$
where $A = [a^{(1)}, \dots, a^{(m)}]$, $Y = [y^{(1)}, \dots, y^{(m)}]$
$db = \frac{1}{m} sum(dZ)$
$dw = \frac{1}{m}Xdz^{T}$
$w = w - \alpha dw$
$b = b - \alpha db$
Multi layered neural networks
First layer, i.e. input layer: provides the input $x$, also called $a^{[0]}$
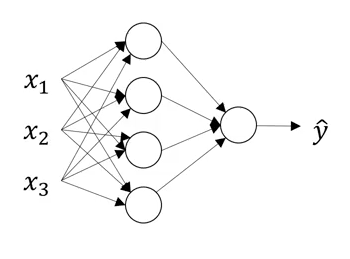
Second layer computes $z^{[1]} = \begin{bmatrix} z^{[1]}_1\\z^{[1]}_2\\\vdots\\z^{[1]}_k\end{bmatrix}$
$=\begin{bmatrix} w^{[1]T}_1 * a^{[0]} + b^{[1]}_1\\ w^{[1]T}_2 * a^{[0]} + b^{[1]}_2\\ \vdots\\w^{[1]T}_k * a^{[0]} + b^{[1]}_k \end{bmatrix}$
and then, $a^{[1]}_i = \sigma(z^{[1]}_i)$
Superscript $[1]$ denotes the first layer of neural network and subscript $i$ denotes the $i^{th}$ element
of the first layer.
Now that you have $a^{[1]}$ ready, can compute $a^{[2]}$ applying similar logic.
Vectorizing computation of $z^{[1]}$ etc.
We stack various $w^{[i]T}$'s below each other and call it $W^{[1]}$, and then call
$z^{[1]} = W^{[1]} * x + b^{[1]}$
or
$z^{[1]} = W^{[1]} * a^{[0]} + b^{[1]}$
and $a^{[1]} = \sigma(z^{[1]})$
Vectorizing across multiple training examples
Now vectorizing across multiple training examples is also not too hard:
As usual, various columns denote various training examples
$Z^{[1]} = W^{[1]} * A + b^{[1]}$
Various activation functions
Activation functions are the source of non linearity.
- sigmoid: $\frac{1}{1 + e^{-z}}$
- tanh: $\frac{1 - e^{-z}}{ 1 + e^z}$
- RelU
- LeakyRelu
Their derivatives:
sigmoid: $g(z) (1 - g(z)$
tanh: $1 - tan^2(z)$
Gradient descent implementation
Parameters are $w^{[1]}$, $b^{[1]}$, $w^{[2]}$, $b^{[2]}$
First layer has $n_x = n^{[0]}$ units, second layer has $n^{[1]}$
units and last layer (for two layer neural net) has $n^{[2]} = 1$
units.
$w^{[1]}$ is $n^{[1]}\times n^{[0]}$ matrix.
$w^{[2]}$ is $n^{[2]}\times n^{[1]}$ matrix.
$b^{[1]}$ is $n^{[1]}\times 1$ matrix.
$b^{[2]}$ is $n^{[2]}\times 1$ matrix.
$J(w^{[1]}, w^{[2]}, b^{[1]}, b^{[2]}) = \frac{1}{m}\sum_{i=1}^mL(\hat{y}, y)$
Repeat {
Compute $\hat{y^{(1)}}, \hat{y^{(2)}}, \hat{y^{(m)}}$
$dw^{[1]} = \frac{dJ}{dw^{[1]}}$, $dw^{[2]} = \frac{dJ}{dw^{[2]}}$
$db^{[1]} = \frac{dJ}{db^{[1]}}$, $db^{[2]} = \frac{dJ}{db^{[2]}}$
$w^{[1]} = w^{[1]} - \alpha dw^{[1]}$
and so on
}
where
 (Image credit: deep learning course on coursera)
(Image credit: deep learning course on coursera)
L-layered neural networks
Similar to 3-layered neural networks.
A note about dimensionality
Let input be $n^{[0]} = n_x$ layered, and $i^{th}$ layer have $n^{[i]}$ neurons.
$W^{[1]}$ has dimension $(n^{[1]}, n^{[0]})$
$W^{[i]}$ has dimension $(n^{[i]}, n^{[i-1]})$
$Z^{[i]}$ has dimension $(n^{[i]}, 1)$
$b^{[i]}$ has dimension $(n^{[i]}, 1)$
Forward/Backward propagation in L-layered neural networks