In this article, I give a simple mathematical exposition of RNN (Recurrent Neural Network) and LSTM (Long Short Term Memory) models- if you are comfortable with matrix multiplication, you will understand RNN and LSTM from this article, even if you don't have prior experience in data science. While there are great resouces on this topic (e.g. this one), most articles on these topics are written by data scientists who assume some data science concepts or notations, which an outside struggles with. Since I learnt it as a non professional data scientist, I might be able to better explain it to you if you are not a data scientist.
At Simpl, we use sequence models heavily and I had a chance to sit with Yash and Nikita, which whose help I was able to understand the models, to a level that makes me feel a bit educated.
While RNNs can be used to solve many problems related to sequential data, we will use the anchor problem of translating one language sentence to another. We have a lot of translations available and we want to use them to train language transaltion model.
Our models don't directly operate on string representations of the words of the language. Rather, they operate on vector representation of those words. A "word embedding" converts words to a row matrix of floating point numbers, and a "softmax" function converts a vector to a word. Understanding word embedding or softmax is outside the scope of this article. Input vectors for a single source language sentence would be denoted by $x_1, x_2, \dots x_t\dots $, and output vectors for a single destination language sentence would be denoted by $y_1, y_2, \dots y_t, \dots$. Note that each of $x_i$ and $y_i$ is a row vector.
In the article below, assume that the each $x_t$ is a $n \times 1$ vector and each $y_t$ is an $o \times 1$ vector.
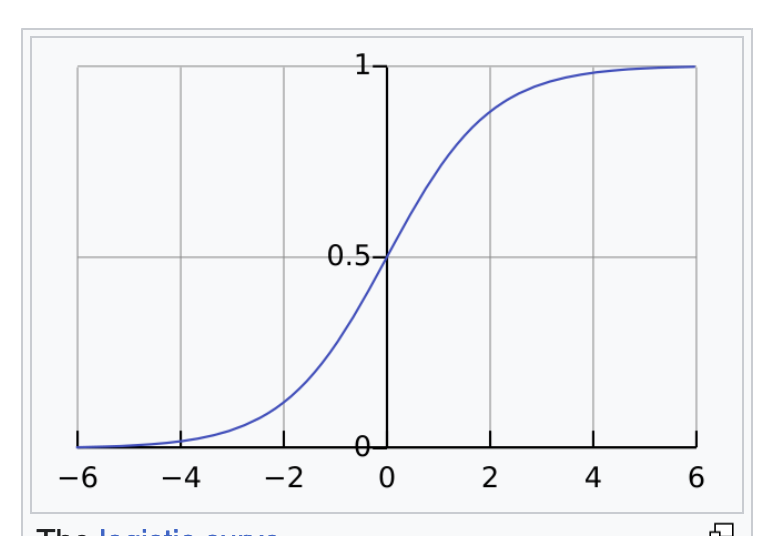
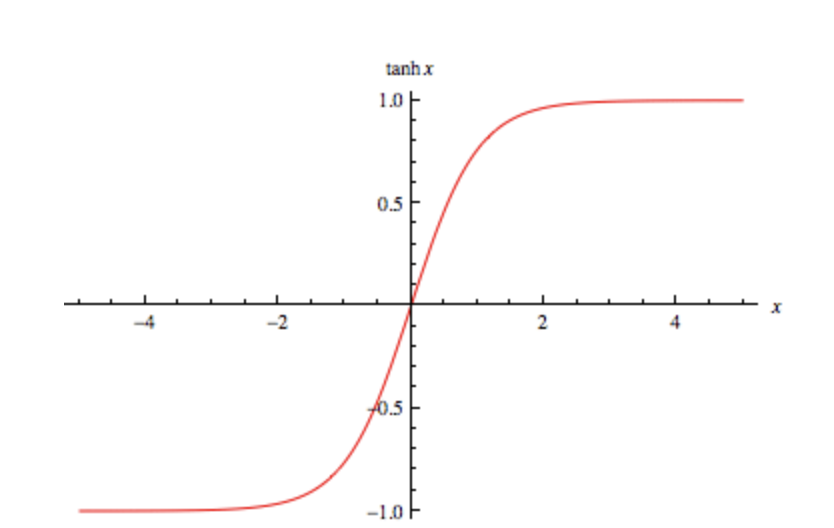
This is the way I look at it:
In any deep learning model, input $x$ (think of $x$ like a column vector)
could have been transfered to output $y$ by successive matrix multiplications:
Here $A_1, A_2, A_3, \dots$ are the matrices that your model learns - their values are set as a part of training. But since $A_3(A_2(A_1))x = (A_3 \times A_2 \times A_1)x$, there is no additional expressive power because of so many matrices - they can all be compressed into just one matrix $B = A_3 \times A_2 \times A_1$.
When you introduce non linearity -
$x \rightarrow \sigma(A_1x) \rightarrow \sigma(A_2 \sigma(A_1(x))) \rightarrow \sigma(A_3\sigma(A_2 \sigma(A_1x))) \rightarrow$then the model becomes more expressive since we cannot collapse all these operations to single operation. This non linearity allows a preferential flow of some values compared to to other to the next step, and that is what gives neural network its power.
In this article, dot(.) denotes matrix multiplication: $$ \begin{bmatrix} 1 & 2\\ 3 & 4\\ \end{bmatrix} . \begin{bmatrix} 5 & 6\\ 7 & 8\\ \end{bmatrix} = \begin{bmatrix} 19 & 22\\ 43 & 50\\ \end{bmatrix} $$
odot($\odot$) denotes element wise multiplication of matrix elements: $$ \begin{bmatrix} 1 & 2\\ 3 & 4\\ \end{bmatrix} \odot \begin{bmatrix} 5 & 6\\ 7 & 8\\ \end{bmatrix} = \begin{bmatrix} 5 & 12\\ 21 & 32\\ \end{bmatrix} $$ If you want to sound sophisticated you call element wise multiplication as Hadamard product.
We can now understanding RNN model. Perhaps we should call it "Vanilla" RNN since even LSTM, GRU etc are also recurrent neural networks.
RNN consists of first deciding $h$ - the size of hidden state, and then finding the following five matrices:
Once we have the above three matrices, output $y_t$ is founding using following equations: $$h_t = \tanh(W_hh_{t-1} + W_xx_t + b_h)$$ $$y_t = W_yh_t + b_y$$
The five matrices need to be found such that on training examples, $y_t$s outputted by the model closely matches with the $y_t$'s of the training data. How it is found - using a technique called backpropagation - is important for practitioners but not important for basic understanding of the model.
There are two main limitations of RNN.
One is the "vanishing/exploding gradient problem". Textbook explanation of this problem presents it as a training problem - as if the standard method of training neural networks - backpropagation, has problems training RNNs. However, I view it as something inherent in RNNs. If you are trying to solve $x^{100} = 100$ then even if you make a small error in the value $x$, you will be way off in your solution. For instance, $(1.01 * x)^{100}$ = $2.7x^{100}$. Thus, a 1% perturbation in the value of $x$ leads to 270% change in the value of $x^{100}$. And so such a model will be susceptible to butterfly effect and the like. And this is what is happening in $h_t = \tanh(W_hh_{t-1} + W_xx_t + b_h)$, where $h_t$ is the only variable capturing everything about the sequence.
Secondly, RNNs struggle to capture long term dependencies in a sentence. (E.g. Ram was going on a trek when he got a phone call, while Priyanka was going a trek when she got a phone call). $h_t$ is the only vector doing everything and it can do only so much.
LSTMs (Long Short Term Model) solve the problem of caputing long term dependencies. To understand it, first, let us understand following five types of entities.
Now, we can see how LSTM works.
LSTM is a function (in mathematical sense) that takes as sequence of input vectors $x_0, x_1, x_2, \dots$ and converts it to sequence of output vectors $o_1, o_2, \dots$.
$$o_t=LSTM(x_{t-1})$$
$o_t$ can then be converted to $y_t$ via a "dense" layer. That is the easy part and we will not talk about that.
So, to understand LSTM, we need to describe what the function $LSTM$ look like. It is a not too complicated:
There we have it. The "only" thing that one needs to do then is to set $W$'s, $U$'s, and $b$'s such that $o_t$'s closely resemeble the output in training data.
Once we know the mathematical formulation, let's try to build intuition around what the model is trying to do.
We start from $c_t$, which is a vector capturing overall (including long term) state of what all has been seen so far. How is $c_t$ updated?
We update $c_t$ as $C_t = f_t \odot C_{t - 1} + i_t \odot \tilde{C_t}$. $\tilde{C_t}$ is the candidate - it is derived from previous hidden state $h_{t-1}$ and next vector in sequence, $x_t$. We multiple previous value of cell state, $C_{t-1}$ with $f_t$ and candidate value $\tilde(C_{t-1}$ with $i_t$ and add these two up to find new $c_t$.
Note that elements of $f_t$ and $i_t$ are all between 0 and 1, and then are called "forget gate" and "input gate". $f_t$ controls how much of previous cell state $C_{t-1}$ enters the new cell state, though I would rather call it "remember gate" than "forget gate". Similarly $i_t$ controls how much of new candidate $\tilde(C_{t})$ enters the new cell state.
$o_t$ is standard (like RNN) function of new input $x_t$ and previous hidden state $h_{t-1}$
Finally $h_t$ is a function of what we have outputted $o_t$ and cell state $c_t$: ($h_t = o_t \odot tanh(C_t)$. I am not super clear on why this is so. Were I designing LSTM, I would have done it $h_t = \tanh(W_1.x_t + W_2.h_{t-1} + W_3.C_t)$. Why have hidden state depend on output? Anyway, specialists must be knowing better.
Alright, so this is all -- in some later article we will get to various recurrent neural architectures - various of LSTMs and GRUs and so on.