Input consists of 4M training positions and 400K test positions.
90% of these positions are got from real games from lichess. Positions have been chosen so that various eval ranges get equal representation. 10% are got from puzzle database of lichess.
Input consists of
18 plane board encoding (12 for pieces, 4 for castling rights, 1 for move, 1 for en passant pawn). A total of ~10M weights in the model (conv and resnet layers).
Total around 10M parameters in the model.
Backbone consists of a convolution layer followed by 8 resenet blocks.
Value head consists of 2 fully connected layers.
Policy head consists of a conv layer leading to 64 * 73 logits which lead to softmax
We represent the moves by 64 x 73 sized probability tensor - more details in the slides.
Huber loss with beta = 0.2 used for value head loss.
Cross entropy loss for policy head. Only the logits corresponding to valid moves participate in cross entropy.
Weight of policy loss is 0.1.
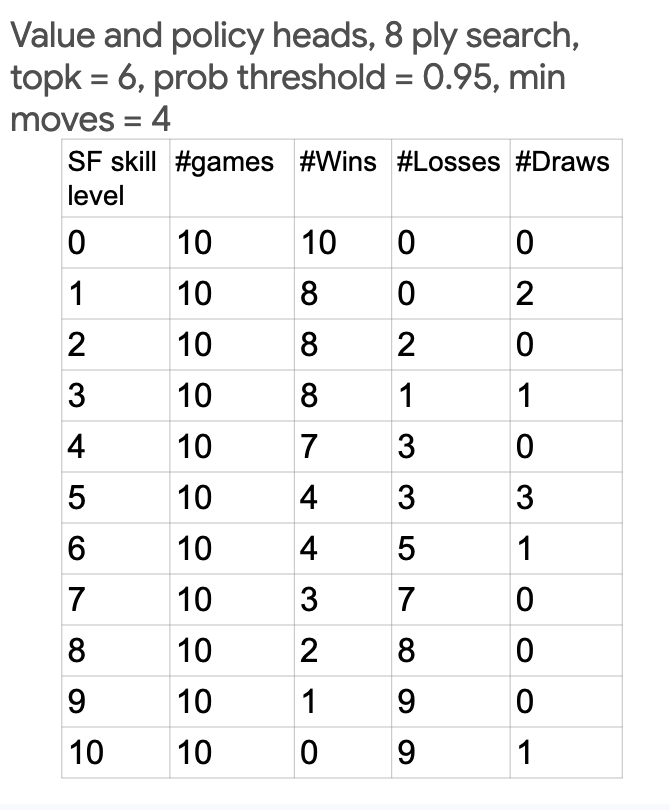
We could go till depth 8 within reasonable move times (as opposed to depth 3 with no value head). We are competitive with level 6 of stockfish, which implies an ELO rating of 2300. 2300 is like FIDE Master level performance. Wow!